|
|
又拍網是一個照片分享社區,從2005年6月至今積累了260萬用戶,1.1億張照片,目前的日訪問量為200多萬。5年的發展歷程里經歷過許多起伏,也積累了一些經驗,在這篇文章里,我要介紹一些我們在技術上的積累。
又拍網和大多數Web2.0站點一樣,構建于大量開源軟件之上,包括MySQL、php、nginx、Python、memcached、redis、Solr、Hadoop和RabbitMQ等等。又拍網的服務器端開發語言主要是php和Python,其中php用于編寫Web邏輯(通過HTTP和用戶直接打交道), 而Python則主要用于開發內部服務和后臺任務。在客戶端則使用了大量的Javascript, 這里要感謝一下MooTools這個JS框架,它使得我們很享受前端開發過程。 另外,我們把圖片處理過程從php進程里獨立出來變成一個服務。這個服務基于nginx,但是是作為nginx的一個模塊而開放REST API。

圖1:開發語言
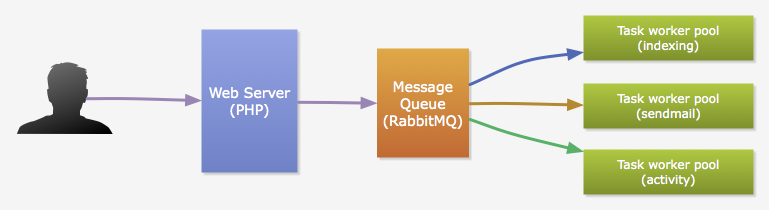
由于php的單線程模型,我們把耗時較久的運算和I/O操作從HTTP請求周期中分離出來, 交給由Python實現的任務進程來完成,以保證請求響應速度。這些任務主要包括:郵件發送、數據索引、數據聚合和好友動態推送(稍候會有介紹)等等。通常這些任務由用戶觸發,并且,用戶的一個行為可能會觸發多種任務的執行。 比如,用戶上傳了一張新的照片,我們需要更新索引,也需要向他的朋友推送一條新的動態。php通過消息隊列(我們用的是RabbitMQ)來觸發任務執行。
數據庫一向是網站架構中最具挑戰性的,瓶頸通常出現在這里。又拍網的照片數據量很大,數據庫也幾度出現嚴重的壓力問題。 因此,這里我主要介紹一下又拍網在分庫設計這方面的一些嘗試。
分庫設計
和很多使用MySQL的2.0站點一樣,又拍網的MySQL集群經歷了從最初的一個主庫一個從庫、到一個主庫多個從庫、 然后到多個主庫多個從庫的一個發展過程。
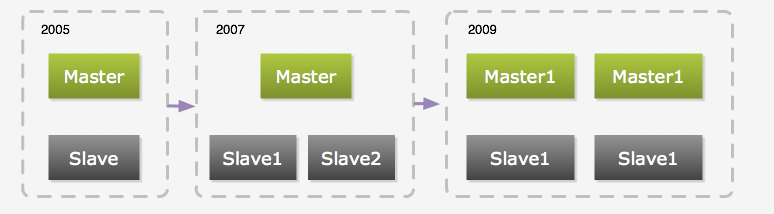
圖3:數據庫的進化過程
最初是由一臺主庫和一臺從庫組成,當時從庫只用作備份和容災,當主庫出現故障時,從庫就手動變成主庫,一般情況下,從庫不作讀寫操作(同步除外)。隨著壓力的增加,我們加上了memcached,當時只用其緩存單行數據。 但是,單行數據的緩存并不能很好地解決壓力問題,因為單行數據的查詢通常很快。所以我們把一些實時性要求不高的Query放到從庫去執行。后面又通過添加多個從庫來分流查詢壓力,不過隨著數據量的增加,主庫的寫壓力也越來越大。
在參考了一些相關產品和其它網站的做法后,我們決定進行數據庫拆分。也就是將數據存放到不同的數據庫服務器中,一般可以按兩個緯度來拆分數據:
垂直拆分:是指按功能模塊拆分,比如可以將群組相關表和照片相關表存放在不同的數據庫中,這種方式多個數據庫之間的表結構不同。
水平拆分:而水平拆分是將同一個表的數據進行分塊保存到不同的數據庫中,這些數據庫中的表結構完全相同。
拆分方式
一般都會先進行垂直拆分,因為這種方式拆分方式實現起來比較簡單,根據表名訪問不同的數據庫就可以了。但是垂直拆分方式并不能徹底解決所有壓力問題,另外,也要看應用類型是否合適這種拆分方式。如果合適的話,也能很好的起到分散數據庫壓力的作用。比如對于豆瓣我覺得比較適合采用垂直拆分, 因為豆瓣的各核心業務/模塊(書籍、電影、音樂)相對獨立,數據的增加速度也比較平穩。不同的是,又拍網的核心業務對象是用戶上傳的照片,而照片數據的增加速度隨著用戶量的增加越來越快。壓力基本上都在照片表上,顯然垂直拆分并不能從根本上解決我們的問題,所以,我們采用水平拆分的方式。
拆分規則
水平拆分實現起來相對復雜,我們要先確定一個拆分規則,也就是按什么條件將數據進行切分。 一般2.0網站都以用戶為中心,數據基本都跟隨用戶,比如用戶的照片、朋友和評論等等。因此一個比較自然的選擇是根據用戶來切分。每個用戶都對應一個數據庫,訪問某個用戶的數據時, 我們要先確定他/她所對應的數據庫,然后連接到該數據庫進行實際的數據讀寫。
那么,怎么樣對應用戶和數據庫呢?我們有這些選擇:
按算法對應
最簡單的算法是按用戶ID的奇偶性來對應,將奇數ID的用戶對應到數據庫A,而偶數ID的用戶則對應到數據庫B。這個方法的最大問題是,只能分成兩個庫。另一個算法是按用戶ID所在區間對應,比如ID在0-10000之間的用戶對應到數據庫A, ID在10000-20000這個范圍的對應到數據庫B,以此類推。按算法分實現起來比較方便,也比較高效,但是不能滿足后續的伸縮性要求,如果需要增加數據庫節點,必需調整算法或移動很大的數據集, 比較難做到在不停止服務的前提下進行擴充數據庫節點。
按索引/映射表對應
這種方法是指建立一個索引表,保存每個用戶的ID和數據庫ID的對應關系,每次讀寫用戶數據時先從這個表獲取對應數據庫。新用戶注冊后,在所有可用的數據庫中隨機挑選一個為其建立索引。這種方法比較靈活,有很好的伸縮性。一個缺點是增加了一次數據庫訪問,所以性能上沒有按算法對應好。
比較之后,我們采用的是索引表的方式,我們愿意為其靈活性損失一些性能,更何況我們還有memcached, 因為索引數據基本不會改變的緣故,緩存命中率非常高。所以能很大程度上減少了性能損失。
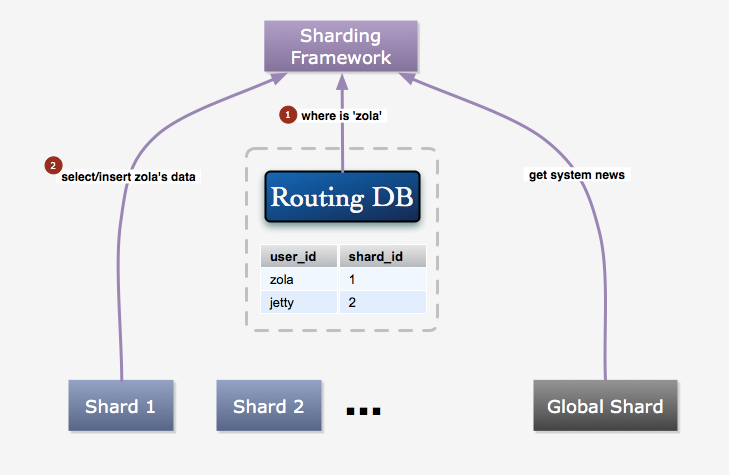
圖4:數據訪問過程
索引表的方式能夠比較方便地添加數據庫節點,在增加節點時,只要將其添加到可用數據庫列表里即可。 當然如果需要平衡各個節點的壓力的話,還是需要進行數據的遷移,但是這個時候的遷移是少量的,可以逐步進行。要遷移用戶A的數據,首先要將其狀態置為遷移數據中,這個狀態的用戶不能進行寫操作,并在頁面上進行提示。 然后將用戶A的數據全部復制到新增加的節點上后,更新映射表,然后將用戶A的狀態置為正常,最后將原來對應的數據庫上的數據刪除。這個過程通常會在凌晨進行,所以,所以很少會有用戶碰到遷移數據中的情況。
當然,有些數據是不屬于某個用戶的,比如系統消息、配置等等,我們把這些數據保存在一個全局庫中。
問題
分庫會給你在應用的開發和部署上都帶來很多麻煩。
不能執行跨庫的關聯查詢
如果我們需要查詢的數據分布于不同的數據庫,我們沒辦法通過JOIN的方式查詢獲得。比如要獲得好友的最新照片,你不能保證所有好友的數據都在同一個數據庫里。一個解決辦法是通過多次查詢,再進行聚合的方式。我們需要盡量避免類似的需求。有些需求可以通過保存多份數據來解決,比如User-A和User-B的數據庫分別是DB-1和DB-2, 當User-A評論了User-B的照片時,我們會同時在DB-1和DB-2中保存這條評論信息,我們首先在DB-2中的photo_comments表中插入一條新的記錄,然后在DB-1中的user_comments表中插入一條新的記錄。這兩個表的結構如下圖所示。這樣我們可以通過查詢photo_comments表得到User-B的某張照片的所有評論, 也可以通過查詢user_comments表獲得User-A的所有評論。另外可以考慮使用全文檢索工具來解決某些需求, 我們使用Solr來提供全站標簽檢索和照片搜索服務。
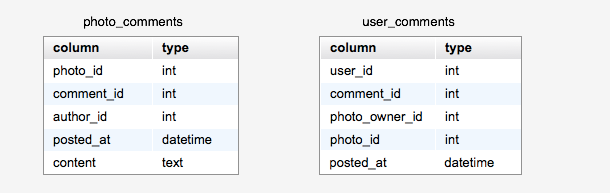
圖5:評論表結構
不能保證數據的一致/完整性
跨庫的數據沒有外鍵約束,也沒有事務保證。比如上面的評論照片的例子, 很可能出現成功插入photo_comments表,但是插入user_comments表時卻出錯了。一個辦法是在兩個庫上都開啟事務,然后先插入photo_comments,再插入user_comments, 然后提交兩個事務。這個辦法也不能完全保證這個操作的原子性。
所有查詢必須提供數據庫線索
比如要查看一張照片,僅憑一個照片ID是不夠的,還必須提供上傳這張照片的用戶的ID(也就是數據庫線索),才能找到它實際的存放位置。因此,我們必須重新設計很多URL地址,而有些老的地址我們又必須保證其仍然有效。我們把照片地址改成/photos/{username}/{photo_id}/的形式,然后對于系統升級前上傳的照片ID, 我們又增加一張映射表,保存photo_id和user_id的對應關系。當訪問老的照片地址時,我們通過查詢這張表獲得用戶信息, 然后再重定向到新的地址。
自增ID
如果要在節點數據庫上使用自增字段,那么我們就不能保證全局唯一。這倒不是很嚴重的問題,但是當節點之間的數據發生關系時,就會使得問題變得比較麻煩。我們可以再來看看上面提到的評論的例子。如果photo_comments表中的comment_id的自增字段,當我們在DB-2.photo_comments表插入新的評論時, 得到一個新的comment_id,假如值為101,而User-A的ID為1,那么我們還需要在DB-1.user_comments表中插入(1, 101 ...)。 User-A是個很活躍的用戶,他又評論了User-C的照片,而User-C的數據庫是DB-3。 很巧的是這條新評論的ID也是101,這種情況很用可能發生。那么我們又在DB-1.user_comments表中插入一行像這樣(1, 101 ...)的數據。 那么我們要怎么設置user_comments表的主鍵呢(標識一行數據)?可以不設啊,不幸的是有的時候(框架、緩存等原因)必需設置。那么可以以user_id、 comment_id和photo_id為組合主鍵,但是photo_id也有可能一樣(的確很巧)。看來只能再加上photo_owner_id了, 但是這個結果又讓我們實在有點無法接受,太復雜的組合鍵在寫入時會帶來一定的性能影響,這樣的自然鍵看起來也很不自然。所以,我們放棄了在節點上使用自增字段,想辦法讓這些ID變成全局唯一。為此增加了一個專門用來生成ID的數據庫,這個庫中的表結構都很簡單,只有一個自增字段id。 當我們要插入新的評論時,我們先在ID庫的photo_comments表里插入一條空的記錄,以獲得一個唯一的評論ID。 當然這些邏輯都已經封裝在我們的框架里了,對于開發人員是透明的。 為什么不用其它方案呢,比如一些支持incr操作的Key-Value數據庫。我們還是比較放心把數據放在MySQL里。 另外,我們會定期清理ID庫的數據,以保證獲取新ID的效率。
實現
我們稱前面提到的一個數據庫節點為Shard,一個Shard由兩個臺物理服務器組成, 我們稱它們為Node-A和Node-B,Node-A和Node-B之間是配置成Master-Master相互復制的。 雖然是Master-Master的部署方式,但是同一時間我們還是只使用其中一個,原因是復制的延遲問題, 當然在Web應用里,我們可以在用戶會話里放置一個A或B來保證同一用戶一次會話里只訪問一個數據庫, 這樣可以避免一些延遲問題。但是我們的Python任務是沒有任何狀態的,不能保證和php應用讀寫相同的數據庫。那么為什么不配置成Master-Slave呢?我們覺得只用一臺太浪費了,所以我們在每臺服務器上都創建多個邏輯數據庫。 如下圖所示,在Node-A和Node-B上我們都建立了shard_001和shard_002兩個邏輯數據庫, Node-A上的shard_001和Node-B上的shard_001組成一個Shard,而同一時間只有一個邏輯數據庫處于Active狀態。 這個時候如果需要訪問Shard-001的數據時,我們連接的是Node-A上的shard_001, 而訪問Shard-002的數據則是連接Node-B上的shard_002。以這種交叉的方式將壓力分散到每臺物理服務器上。 以Master-Master方式部署的另一個好處是,我們可以不停止服務的情況下進行表結構升級, 升級前先停止復制,升級Inactive的庫,然后升級應用,再將已經升級好的數據庫切換成Active狀態, 原來的Active數據庫切換成Inactive狀態,然后升級它的表結構,最后恢復復制。 當然這個步驟不一定適合所有升級過程,如果表結構的更改會導致數據復制失敗,那么還是需要停止服務再升級的。
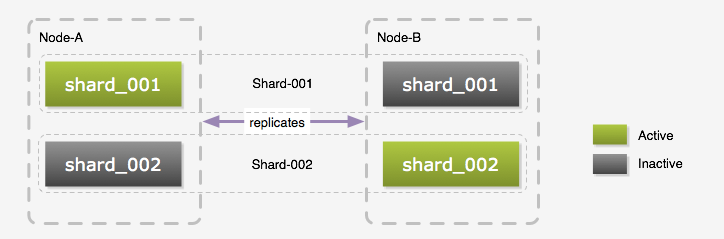
圖6:數據庫布局
前面提到過添加服務器時,為了保證負載的平衡,我們需要遷移一部分數據到新的服務器上。為了避免短期內遷移的必要,我們在實際部署的時候,每臺機器上部署了8個邏輯數據庫, 添加服務器后,我們只要將這些邏輯數據庫遷移到新服務器就可以了。最好是每次添加一倍的服務器, 然后將每臺的1/2邏輯數據遷移到一臺新服務器上,這樣能很好的平衡負載。當然,最后到了每臺上只有一個邏輯庫時,遷移就無法避免了,不過那應該是比較久遠的事情了。
我們把分庫邏輯都封裝在我們的php框架里了,開發人員基本上不需要被這些繁瑣的事情困擾。下面是使用我們的框架進行照片數據的讀寫的一些例子:
<?php
$Photos = new ShardedDBTable('Photos', 'yp_photos', 'user_id', array(
'photo_id' => array('type' => 'long', 'primary' => true, 'global_auto_increment' => true),
'user_id' => array('type' => 'long'),
'title' => array('type' => 'string'),
'posted_date' => array('type' => 'date'),
));
$photo = $Photos->new_object(array('user_id' => 1, 'title' => 'Workforme'));
$photo->insert();
// 加載ID為10001的照片,注意第一個參數為用戶ID
$photo = $Photos->load(1, 10001);
// 更改照片屬性
$photo->title = 'Database Sharding';
$photo->update();
// 刪除照片
$photo->delete();
// 獲取ID為1的用戶在2010-06-01之后上傳的照片
$photos = $Photos->fetch(array('user_id' => 1, 'posted_date__gt' => '2010-06-01'));
?>
it知識庫:又拍網架構中的分庫設計,轉載需保留來源!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。