|
|
最近,剛跳槽到一新公司,就遇到生產數據庫晚上突然出現大面積中斷,并持續近一小時,而發生事故時,我沒有在現場,錯過了直接獲取信息的機會;過后boss要求追查原因,于是艱難的排查過程開始了。
開始以為是數據庫某個JOB運行出現異常引起或者是因為程序里面哪個鳥人寫了垃圾語句造成了大面積的死鎖,于是將收集的trace信息拿到本地分析,從收集到的trace信息看,數據庫在19:49:28時出現了鎖,系統cancel了它,而且是連續三個,之后數據庫大部分連接都是Abort了。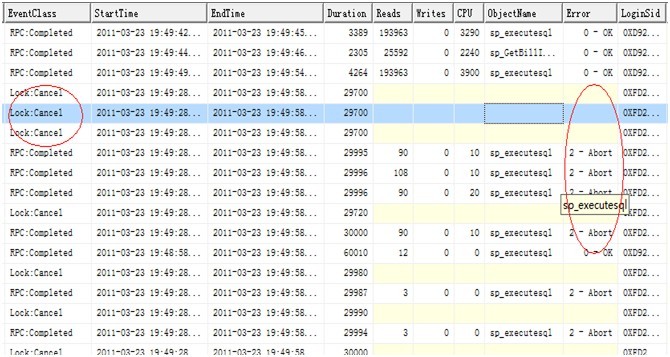 初步估計應該是死鎖了,首先想到的就是因為數據庫更新語句造成,于是查找Agent里面是否有對應時間的JOB運行,結果沒有匹配的,然后分析trace文件里面是否有該時間段內運行的長Update、Insert或者Delete語句,查了半天也沒發現,汗。。。,調查長查詢,還是沒有,狂汗。。。
初步估計應該是死鎖了,首先想到的就是因為數據庫更新語句造成,于是查找Agent里面是否有對應時間的JOB運行,結果沒有匹配的,然后分析trace文件里面是否有該時間段內運行的長Update、Insert或者Delete語句,查了半天也沒發現,汗。。。,調查長查詢,還是沒有,狂汗。。。
Trace文件分析來分析去也沒辦法定位到具體語句(Trace 文件中只抓取了運行時間超過2秒或者讀大于10000的記錄),看來問題不是那么簡單了;光根據Trace文件信息想要找到兇手估計不可能了,于是把Windows日志和數據庫錯誤日志都查了一遍,也沒有發現任何異常,難道是無頭案。。。(沒查到任何信息,擔心飯碗不保了)
想來想去,也問了一些牛人,都沒有啥結果,看來通過手頭上現有的資料估計要找出問題是沒多少希望了,只能另辟蹊徑;既然可以肯定是因為死鎖造成的,那說明數據庫里面肯定存在資源的不一致訪問或者競爭,那就從死鎖下手,于是先清空掉當前的數據庫錯誤日志文件,再打開1204和1222跟蹤標志,等待魚兒上鉤。
DBCC errorlog DBCC TRACEON (1204, 1222, -1); DBCC tracestatus
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。