|
|
索引的優(yōu)點(diǎn):這個(gè)顯而易見(jiàn),正確的索引會(huì)大大提高數(shù)據(jù)查詢(xún),對(duì)結(jié)果進(jìn)行排序、分組的操作效率。
索引的缺點(diǎn):優(yōu)點(diǎn)顯而易見(jiàn),同樣缺點(diǎn)也是顯而易見(jiàn):
1:創(chuàng)建索引需要額外的磁盤(pán)空間,索引最大一般為表大小的1.2倍左右。
2:在表數(shù)據(jù)修改時(shí),例如增加,刪除,更新,都需要維護(hù)索引表,這是需要系統(tǒng)開(kāi)銷(xiāo)的。
3:不合理的索引設(shè)計(jì)非但不能利于系統(tǒng),反而會(huì)使系統(tǒng)性能下降。例如我們?cè)谝粋€(gè)創(chuàng)建有非聚集索引的列上做范圍查詢(xún),此列的索引不會(huì)起到任何的優(yōu)化效果,反而由于數(shù)據(jù)的修改而需要維護(hù)索引表,從而影響了對(duì)數(shù)據(jù)修改的性能。
實(shí)際例子:還是拿前兩篇文章的學(xué)生表來(lái)講吧,要查詢(xún)成績(jī)?cè)?0分以上的學(xué)生信息select * from student where score>50。學(xué)生表包含了100000行記錄,而且學(xué)分是隨機(jī)生成的,這樣從數(shù)據(jù)量以及數(shù)據(jù)分布上都有一定的保障。
第一種情況:學(xué)生表有索引
1:存在聚集索引,但聚集索引不在學(xué)分上,這里只分析學(xué)分不是聚集索引的情況。
(1): 學(xué)分上沒(méi)有索引。此時(shí)SQL會(huì)通過(guò)聚集索引來(lái)查找數(shù)據(jù),這點(diǎn)估計(jì)大家都會(huì)知道。
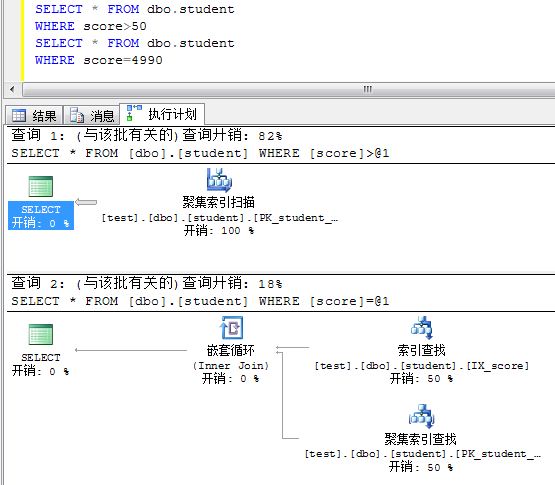
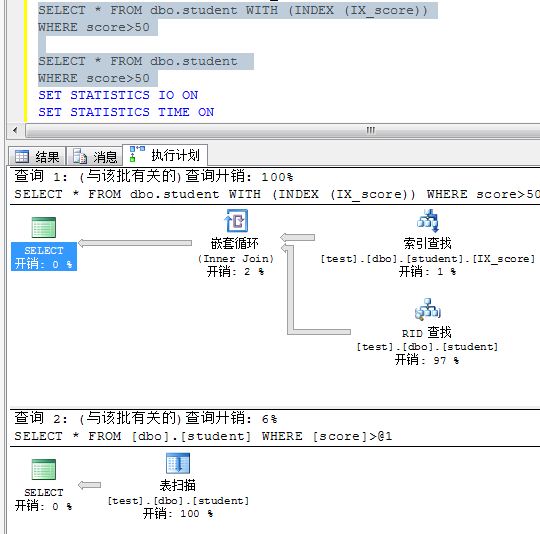
(2): 學(xué)分上有索引。這種情況,SQL會(huì)使用上學(xué)分上的索引嗎?這個(gè)問(wèn)題估計(jì)不是每個(gè)人都能回答正確的。既然學(xué)分上有索引,而where中又有此列,理應(yīng)使用了索引,但實(shí)際情況并沒(méi)有使用索引。因?yàn)槌霈F(xiàn)了范圍查找,如果一個(gè)索引一個(gè)索引的比較,在性能上比起直接按聚集索引查找全部數(shù)據(jù)后再過(guò)濾來(lái)的差。那學(xué)分上的索引什么時(shí)候 SQL會(huì)優(yōu)先考慮呢?當(dāng)score指定為一個(gè)具體值時(shí),就能使用學(xué)分索引查找了。從下圖的SQL執(zhí)行計(jì)劃可以得知。
2:不存在聚集索引。
(1):在學(xué)分上沒(méi)有索引,其它字段有索引,這種情況就會(huì)出現(xiàn)表掃描。
(2):在學(xué)分上有索引,是否會(huì)按照學(xué)分上的索引進(jìn)行查找呢?由于上面的表數(shù)據(jù)量也不少,一般會(huì)認(rèn)為SQL不會(huì)采用表掃描,因?yàn)闀?huì)查找全部記錄,但實(shí)際情況表明SQL對(duì)于范圍查詢(xún)也行采用表掃描而不是按學(xué)生索引查詢(xún)。我們也可以強(qiáng)制SQL按學(xué)分查詢(xún),于是有下面的SQL執(zhí)行計(jì)劃比較,我們可以清楚的看出,強(qiáng)制使用學(xué)分做為索引查詢(xún)比表搜索的性能要差很多。
第二種情況:學(xué)生表沒(méi)有索引。這個(gè)情況沒(méi)有分析的價(jià)值。
什么字段不適合創(chuàng)建索引?
1:不經(jīng)常使用的列,這種索引帶來(lái)缺點(diǎn)遠(yuǎn)大于帶來(lái)的優(yōu)點(diǎn)。
2:邏輯性的字段,例如性別字段等等,匹配的記錄太多,和表掃描比起來(lái)不相上下。
3:字段內(nèi)容特別大的字段,例如text等,這會(huì)大大增大索引所占用的空間以及索引更新時(shí)的速度。
我們說(shuō)SQL在維護(hù)索引時(shí)要消耗系統(tǒng)資源,那么SQL維護(hù)索引時(shí)究竟消耗了什么資源?會(huì)產(chǎn)生哪些問(wèn)題?究竟怎樣才能優(yōu)化字段的索引?
第一:當(dāng)數(shù)據(jù)頁(yè)達(dá)到了8K(數(shù)據(jù)頁(yè)最大為8K) 容量,如此時(shí)發(fā)生插入或更新數(shù)據(jù)的操作,將導(dǎo)致頁(yè)的分裂。
1、聚集索引的情況下:聚集索引將被插入和更新的行指向特定的頁(yè),該頁(yè)由聚集索引關(guān)鍵字決定;
2、只有堆的情況下:有空間就可以插入新的行,對(duì)行數(shù)據(jù)的更新需要更多的空間,如果大于了當(dāng)前頁(yè)的可用空間,行就被移到新的頁(yè)中,且在原位置留下一個(gè)轉(zhuǎn)發(fā)指針,指向被移動(dòng)的新行,如果具有轉(zhuǎn)發(fā)指針的行又被移動(dòng)了,那么原來(lái)的指針將重新指向新的位置;
3、堆中有非聚集索引,盡管插入和更新操作,不會(huì)發(fā)生頁(yè)分裂,但非聚集索引上仍然產(chǎn)生頁(yè)分裂。
總結(jié):無(wú)論有無(wú)索引,很多數(shù)據(jù)將保留在老頁(yè)面,其它將放入新頁(yè)面,并且新頁(yè)面可能被分配到任何可用的頁(yè),頻繁頁(yè)分裂,表會(huì)產(chǎn)生大量數(shù)據(jù)碎片,直接造成I/O 效率下降。
引出問(wèn)題:為什么數(shù)據(jù)庫(kù)對(duì)于varchar最大值設(shè)置為8000,而不是10000呢?
答:是由于數(shù)據(jù)頁(yè)大小最大為8K。
第二:針對(duì)上述索引可能造成的頁(yè)分頁(yè)的解決方案,填充因子。
創(chuàng)建索引時(shí),可以為索引指定一個(gè)填充因子,在索引的每個(gè)葉級(jí)頁(yè)面上保留一定百分比的空間,將來(lái)數(shù)據(jù)可以進(jìn)行擴(kuò)充和減少頁(yè)分裂。值從0到100的百分比數(shù)值,100 時(shí)表示將數(shù)據(jù)頁(yè)填滿(mǎn)。不對(duì)數(shù)據(jù)進(jìn)行更改時(shí)(例如只讀表中)才用此設(shè)置,實(shí)用價(jià)值不大。值越小則數(shù)據(jù)頁(yè)上的空閑空間越大,可以減少在索引增長(zhǎng)過(guò)程中進(jìn)行頁(yè)分裂,但需要占用更多的硬盤(pán)空間。填充因子也不能設(shè)置過(guò)小,過(guò)小會(huì)影響SQL的讀取性能,因?yàn)樘畛湟蜃釉斐蓴?shù)據(jù)頁(yè)的增多。一般我們公司設(shè)置的填充因子是80。
索引是否是一塵不變的?
隨著業(yè)務(wù)的變化,數(shù)據(jù)的變化,會(huì)發(fā)生有些索引的用處可能發(fā)生變化,例如:
1:原來(lái)主要靠用戶(hù)名搜索記錄,現(xiàn)在業(yè)務(wù)更改為按用戶(hù)所在城市搜索等等,此時(shí)我們需要即時(shí)變更表索引以適應(yīng)新業(yè)務(wù)的變化,即數(shù)據(jù)和使用模式發(fā)生了大幅度變化。
2:系統(tǒng)上線(xiàn)前不合理的索引,隨著數(shù)據(jù)的增加,缺點(diǎn)越來(lái)越明顯,此時(shí)需要調(diào)整索引。
3:隨著數(shù)據(jù)的增加,產(chǎn)生了越來(lái)越多的頁(yè)分裂,導(dǎo)致索引性能越來(lái)越低。
上面的幾種情況,我們就需要選擇重建索引來(lái)徹底解決問(wèn)題。
總結(jié)索引使用原則:
1:不要索引數(shù)據(jù)量不大的表,對(duì)于小表來(lái)講,表掃描的成本并不高。
2:不要設(shè)置過(guò)多的索引,在沒(méi)有聚集索引的表中,最大可以設(shè)置249個(gè)非聚集索引,過(guò)多的索引首先會(huì)帶來(lái)更大的磁盤(pán)空間,而且在數(shù)據(jù)發(fā)生修改時(shí),對(duì)索引的維護(hù)是特別消耗性能的。
3:合理應(yīng)用復(fù)合索引,有某些情況下可以考慮創(chuàng)建包含所有輸出列的覆蓋索引。
4:對(duì)經(jīng)常使用范圍查詢(xún)的字段,可能考慮聚集索引。
5:避免對(duì)不常用的列,邏輯性列,大字段列創(chuàng)建索引。
it知識(shí)庫(kù):軟件開(kāi)發(fā)人員真的了解SQL索引嗎(索引使用原則),轉(zhuǎn)載需保留來(lái)源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。